- 精選文章
文章專區
2016-05-01電腦如何擊敗世界棋王?—AlphaGo人工智慧技術
557 期
Author 作者
顏士淨/臺大資訊博士,目前是東華資工系教授,IEEE資深會員,也擔任人工智慧學會與臺灣電腦對局學會的理事。研究領域為人工智慧與電腦對局,本身是圍棋六段,主持的實驗室發展許多圍棋、象棋等程式。
由Google DeepMind所開發的人工智慧圍棋程式── AlphaGo,在今(2016)年3月以四勝一敗的戰績勝過南韓棋王李世石。此一消息震撼了資訊界與圍棋界,造就人工智慧的里程碑。AlphaGo主要是以深度學習網路(deep learning networks)與蒙地卡羅樹搜尋(Monte Carlo Tree Search, MCTS)的技術來開發,並以自我學習的方式提高棋力。Google DeepMind 在三年前開始網羅電腦圍棋的專家,加上充沛的計算資源與大量的資訊人才,終於完成此一壯舉,不但影響了圍棋的發展,也讓人開始思考人工智慧對人類未來的影響。
電腦對局(computer game)是人工智慧領域中最吸引人的課題之一,也是衡量人工智慧的一個好方式,如1997年美國科技公司IBM在超級電腦上開發出來的「深藍(Deepblue)」,戰勝了西洋棋冠軍卡斯帕洛夫(Garry Kasparov)。對於目前世界上較廣為流傳的棋盤遊戲,我們可分析其複雜度(表一)。其中複雜度以該棋類起始盤面之後的所有可能變化為衡量標準。整體來說,西洋跳棋(checkers)、黑白棋(Othello)在電腦上的發展,已到達超越人類的程度;西洋棋、象棋、日本將棋程式,電腦也已到達職業棋士的水準;而Google DeepMind在此次挑戰圍棋九段成功,登上了21世紀人工智慧電腦對局的聖母峰,將永留人工智慧電腦對局的青史。
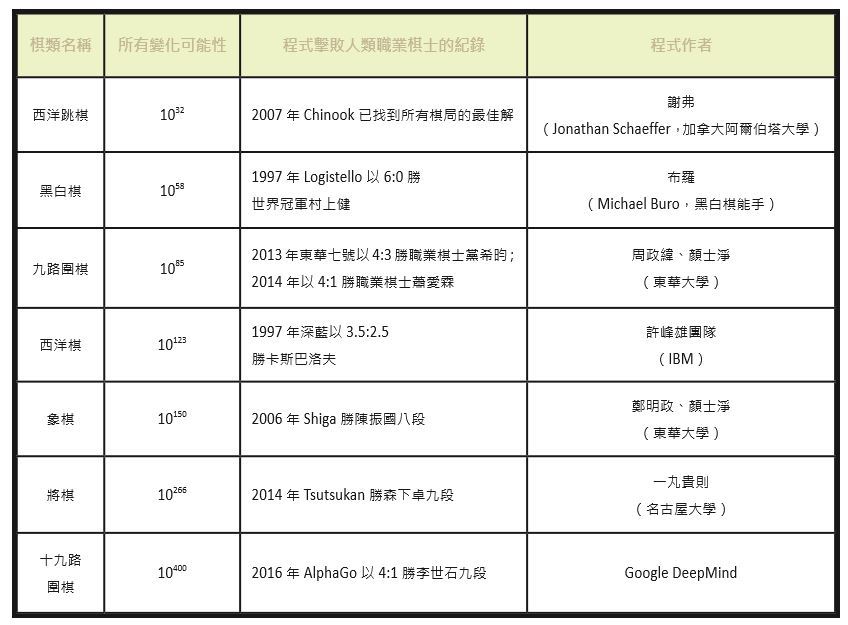
表一:人工智慧已在7種代表性棋類上戰勝人類新型演算法提高搜尋效率
由表一中可以看出圍棋的複雜度相對很高,這是因為圍棋的盤面都比較大,如果使用暴力法搜尋,在每層的分支數過多的情況下,將無法搜尋很深。因此,一些全域搜尋的方式通常不適合用於圍棋這種複雜度太高的遊戲。因此,2006年蒙地卡羅樹搜尋演算法的提出,使得電腦圍棋的研究有驚人的突破。
這種全域搜尋的演算法,以蒙地卡羅模擬演算法作為局面評估的依據,判斷形勢的良窳。又利用上界信賴演算法(Upper Confidence Bound, UCB)使得搜尋樹可以往較優秀的子點展開成為一棵不平衡樹,從而達到裁剪的目的以增加搜尋深度,適用於解決高複雜度的問題。……【更多內容請閱讀科學月刊第557期】